
Data & IA
Qu’est-ce qu’un data warehouse ?
5
min de lecture
Sommaire
Introduction
À mesure que les entreprises multiplient les outils digitaux, la donnée devient omniprésente… mais aussi fragmentée. ERP, CRM, logiciels métier, outils marketing, plateformes e-commerce : chacun produit sa propre vision de la réalité.
Le data warehouse répond à un besoin devenu central : rassembler, structurer et fiabiliser la donnée pour piloter l’entreprise.
Contrairement aux bases opérationnelles, conçues pour exécuter des actions, le data warehouse est pensé pour analyser, comprendre et décider. Il constitue le socle de toute stratégie data sérieuse, qu’il s’agisse de pilotage de la performance, de reporting réglementaire ou de projets analytiques avancés.
Qu’est-ce qu’un data warehouse ?
Un data warehouse est une plateforme centralisée qui collecte les données issues de multiples systèmes sources, les historise, les transforme et les met à disposition pour l’analyse.
Sa vocation n’est pas d’exécuter des transactions en temps réel, mais de fournir une vision consolidée, fiable et historisée de l’activité de l’entreprise.
On y retrouve généralement :
des données commerciales,
des données financières,
des données logistiques,
des données marketing ou opérationnelles.
Le data warehouse devient ainsi la source de vérité sur laquelle s’appuient les tableaux de bord, les analyses stratégiques et les décisions managériales.
À quoi sert un data warehouse dans une entreprise ?
Un data warehouse permet de répondre à des questions que les outils opérationnels seuls ne peuvent pas traiter efficacement :
Quelle est l’évolution réelle de notre performance dans le temps ?
Quels sont nos indicateurs fiables et partagés par tous ?
Où se situent les écarts entre prévisionnel et réel ?
Comment croiser des données issues de systèmes différents ?
Il joue un rôle clé dans :
le pilotage stratégique,
la prise de décision,
la conformité et le reporting,
l’industrialisation des usages data.
Cas concrets d’usage métier
En finance, le data warehouse permet de fiabiliser les indicateurs clés (chiffre d’affaires, marge, trésorerie), de comparer les périodes dans le temps et de sécuriser le reporting sans retraitements manuels chronophages.
Côté produit ou opérations, il aide à analyser les usages, identifier les points de friction, suivre la performance des processus et croiser des données issues de systèmes hétérogènes (outil métier, support, CRM).
Selon la taille de l’entreprise :
une PME l’utilise pour structurer ses indicateurs et sortir d’Excel,
une scale-up pour fiabiliser sa croissance et aligner toutes les équipes sur les mêmes chiffres,
un grand groupe pour industrialiser le pilotage et harmoniser la donnée à grande échelle.
Les grandes briques fonctionnelles d’un data warehouse moderne
Un data warehouse moderne ne se limite pas à une base de données analytique.
Il repose sur une chaîne complète de traitement de la donnée, structurée en plusieurs briques complémentaires.
1. Les sources de données
Le point de départ est constitué des systèmes sources de l’entreprise : ERP, CRM, applications métier, outils marketing, fichiers ou APIs externes.
Ces systèmes sont conçus pour faire fonctionner l’activité quotidienne et garantir l’exécution des processus métier.
C’est à ce niveau, et uniquement à ce niveau, que les problèmes de qualité de donnée doivent être corrigés à la source, avant toute exploitation analytique.
Le data warehouse ne les remplace pas : il les fédère.
2. La couche de collecte et d’ingestion
Cette brique permet de rapatrier les données depuis les systèmes sources vers la plateforme analytique.
L’ingestion peut être :
en batch (souvent quotidienne),
ou plus fréquente selon les besoins métier.
À ce stade, la donnée est volontairement peu transformée.
L’objectif est de sécuriser les flux, de conserver une trace fidèle de l’existant et de préparer les traitements analytiques ultérieurs.
3. La couche de stockage et d’historisation — socle Bronze
Le data warehouse est conçu pour stocker et historiser l’ensemble des données dans le temps, afin de permettre l’analyse des évolutions, la comparaison de périodes et l’étude des tendances.
Dans les architectures modernes, cette fonction est principalement portée par la couche Bronze, qui constitue le socle de référence de la plateforme data.
La donnée Bronze est :
brute, directement issue des systèmes sources,
conservée dans une forme fidèle à l’existant,
historisée et traçable,
utilisée comme point d’appui pour l’ensemble des traitements en aval.
Elle n’a pas vocation à être exploitée directement par les métiers, mais à garantir la fiabilité, l’auditabilité et la reproductibilité des traitements analytiques réalisés dans les couches suivantes.
4. La couche de transformation et de préparation des données — Silver et Gold
Cette brique correspond aux niveaux de maturité Silver et Gold du data warehouse.
Elle constitue la brique la plus structurante, car elle permet de faire monter la donnée en valeur, depuis la donnée brute historisée jusqu’à la donnée prête à être consommée.
La couche Silver — donnée nettoyée et structurée
La couche Silver correspond à une donnée dite cleaned, exploitable pour l’analyse.
À ce stade, les données sont :
nettoyées, typées et dédupliquées,
organisées selon un schéma standardisé,
enrichies par des jointures de base lorsque nécessaire,
soumises à une validation de la qualité (valeurs nulles gérées, formats uniformisés),
utilisables pour l’exploration et les analyses ad hoc.
Il ne s’agit pas de corriger la donnée au sens métier, mais de :
identifier les incohérences,
les documenter,
les standardiser pour l’analyse,
et, si nécessaire, les compenser temporairement dans les usages analytiques, tout en conservant une traçabilité claire vers la donnée d’origine.
La couche Gold — donnée orientée métier
La couche Gold correspond au niveau de maturité le plus avancé de la donnée.
Elle est conçue pour répondre directement aux cas d’usage métier et décisionnels.
Les données y sont :
agrégées et modélisées pour des cas d’usage précis,
organisées en tables dénormalisées,
accompagnées de KPIs pré-calculés,
optimisées pour la performance des requêtes BI,
exprimées dans un vocabulaire métier partagé,
prêtes à être consommées par les utilisateurs finaux.
Les règles de calcul communes à l’entreprise sont principalement appliquées à ce niveau, tout en conservant une traçabilité complète vers les couches Silver et Bronze.
5. La couche de restitution et de BI
Les données préparées sont ensuite exposées vers :
des outils de Business Intelligence,
des tableaux de bord,
des reportings métiers,
parfois des applications ou produits data.
L’enjeu est de fournir des indicateurs lisibles, performants et actionnables.
6. La gouvernance et la sécurité des données
Un data warehouse moderne intègre des mécanismes de gouvernance :
documentation des données et la sémantique associée
gestion fine des droits d’accès,
traçabilité des données,
documentation des indicateurs,
sécurisation des usages.
Sans gouvernance, la donnée devient incompréhensible.
Avec une gouvernance claire, elle devient un véritable levier de pilotage.
Data warehouse vs data lake vs data lakehouse
Avant de choisir une architecture data, il est essentiel de bien comprendre les différences entre data warehouse, data lake et data lakehouse , trois concepts souvent confondus mais conçus pour des usages bien distincts.
Le data warehouse, le data lake et le data lakehouse répondent à des besoins différents, bien qu’ils soient souvent confondus.
Le data warehouse est conçu pour l’analyse structurée. Il stocke des données propres, modélisées et historisées, prêtes à être exploitées par les équipes métiers via des tableaux de bord fiables.
Le data lake stocke de grands volumes de données brutes, dans leur format natif (structuré ou non). Il offre une grande flexibilité, mais nécessite des compétences data avancées pour être exploité correctement.
La tendance est au data lakehouse qui combine les deux approches : les technologies du data lake pour la couche Bronze et la performance analytique du data warehouse.
Conclusion : un data warehouse comme cartographie fonctionnelle de la plateforme data
Un data warehouse moderne ne se résume ni à un simple entrepôt de données, ni à une succession d’outils techniques.
Il constitue avant tout une cartographie fonctionnelle de la plateforme data de l’entreprise, structurée autour de briques clairement identifiées : gouvernance, ingestion, stockage, transformation et restitution.
Chaque brique répond à un rôle précis et s’inscrit dans une logique d’ensemble.
Ce n’est pas l’addition de technologies qui crée la valeur, mais l’articulation cohérente de ces briques, leur alignement avec les usages métiers et leur capacité à évoluer dans le temps sans remettre en cause l’existant.
Le schéma ci-dessous illustre cette vision : un data warehouse pensé comme un socle structurant, capable d’absorber la complexité des systèmes sources, d’organiser la montée en maturité de la donnée (Bronze, Silver, Gold) et de soutenir durablement les usages analytiques et décisionnels. 👇
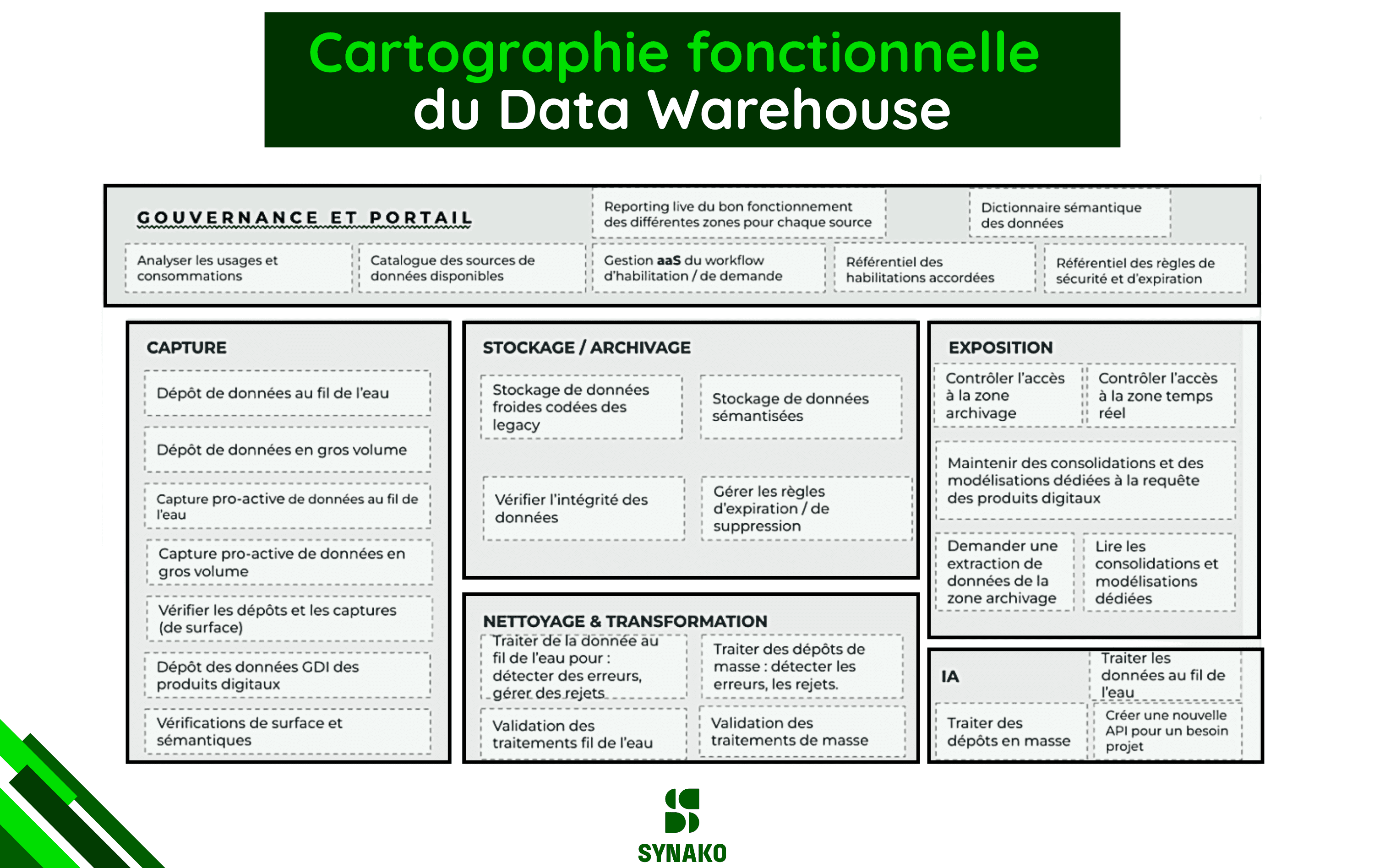
Erreur à éviter :
un data warehouse n’est pas conçu pour faire du “temps réel” contrairement à la base de données de production, il produit une donnée fiable, documentée, historisée, gouvernée et exploitable, qu’elle soit utilisée pour du reporting, de la BI, de l’analyse avancée ou des cas d’usage métiers plus complexes. La logique Bronze / Silver / Gold permet précisément d’organiser cette progression de valeur, depuis la donnée brute jusqu’à la donnée prête à être consommée.
Le data warehause ne doit pas être utilisé en middleware pour faire de l’intégration entre 2 systèmes opérationnels.
De l’architecture data à la valeur métier : l’approche Synako
Chez Synako, nous concevons des architectures data sur mesure, data warehouse, data lakehouse et plateformes analytiques, pensées comme de véritables produits internes :
alignées avec les usages métiers réels,
intégrées à l’existant (ERP, CRM, outils métiers),
gouvernées dès la conception,
et capables d’évoluer sans refonte permanente.
L’objectif est de construire un actif stratégique durable, qui serve à la fois le pilotage, la performance opérationnelle et les produits digitaux de l’entreprise.
Si vous êtes dirigeant, CTO ou responsable data, il y a de fortes chances que vous vous posiez déjà certaines de ces questions :
Vos équipes passent-elles encore trop de temps à réconcilier des chiffres plutôt qu’à les exploiter ?
Disposez-vous d’une vision fiable et partagée de la performance, ou chaque service travaille-t-il avec ses propres indicateurs ?
Votre architecture data actuelle vous permet-elle d’absorber de nouveaux usages sans complexifier le système existant ?
Les décisions stratégiques reposent-elles sur une donnée gouvernée et traçable, ou sur des extractions ponctuelles difficiles à maintenir ?
Chez Synako, ce type de questionnement constitue souvent le point de départ d’un audit ciblé, permettant de clarifier les priorités, d’objectiver les enjeux et de poser les bases d’une plateforme data réellement adaptée aux usages de l’entreprise.

